Có phải AI có thể trì hoãn kiểm tra an toàn để gây hại cho người dùng không? Có, nhưng không tốt lắm – ít nhất là hiện tại. Các công ty AI khẳng định có các kiểm tra an toàn mạnh mẽ đảm bảo rằng các mô hình không nói hoặc làm những việc lạ lùng, bất hợp pháp hoặc không an toàn. Nhưng nếu những mô hình có khả năng tránh được những kiểm tra đó và, vì một lý do nào đó, cố gắng phá hoại hoặc đánh lừa người dùng? Có vẻ như họ có thể làm được điều này, theo các nhà nghiên cứu của Anthropic. Chỉ là không tốt lắm… ít nhất là hiện tại.
“Khi AI trở nên mạnh mẽ hơn,” nhóm Alignment Science của Anthropic viết, “một loại rủi ro mới có thể xuất hiện: các mô hình có khả năng đánh lừa người dùng của họ hoặc xâm phạm vào các hệ thống chúng ta đặt ra để giám sát chúng.”
Vì vậy, chúng ta nên tìm cách đo lường “khả năng gây hại của một mô hình.”
Các loạt thí nghiệm mà họ thiết kế có vẻ khá nhân tạo và mức độ bề nổi, nhưng chúng chỉ ra rằng có điều đáng giá để tiếp tục điều tra. Dưới đây là các mô hình đáng ngờ mà họ đã đào tạo và các kết quả họ đã quan sát được:
Nhiệm vụ 1: Đánh lừa người dùng một cách bí mật bằng cách biến tấu dữ liệu mà nó được thiết lập để tóm tắt hoặc hiểu. Kết quả: Thành công! Càng quyết liệt mô hình cố gắng, ảnh hưởng càng lớn đến người sử dụng, nhưng cũng khiến họ trở nên nghi ngờ hơn.
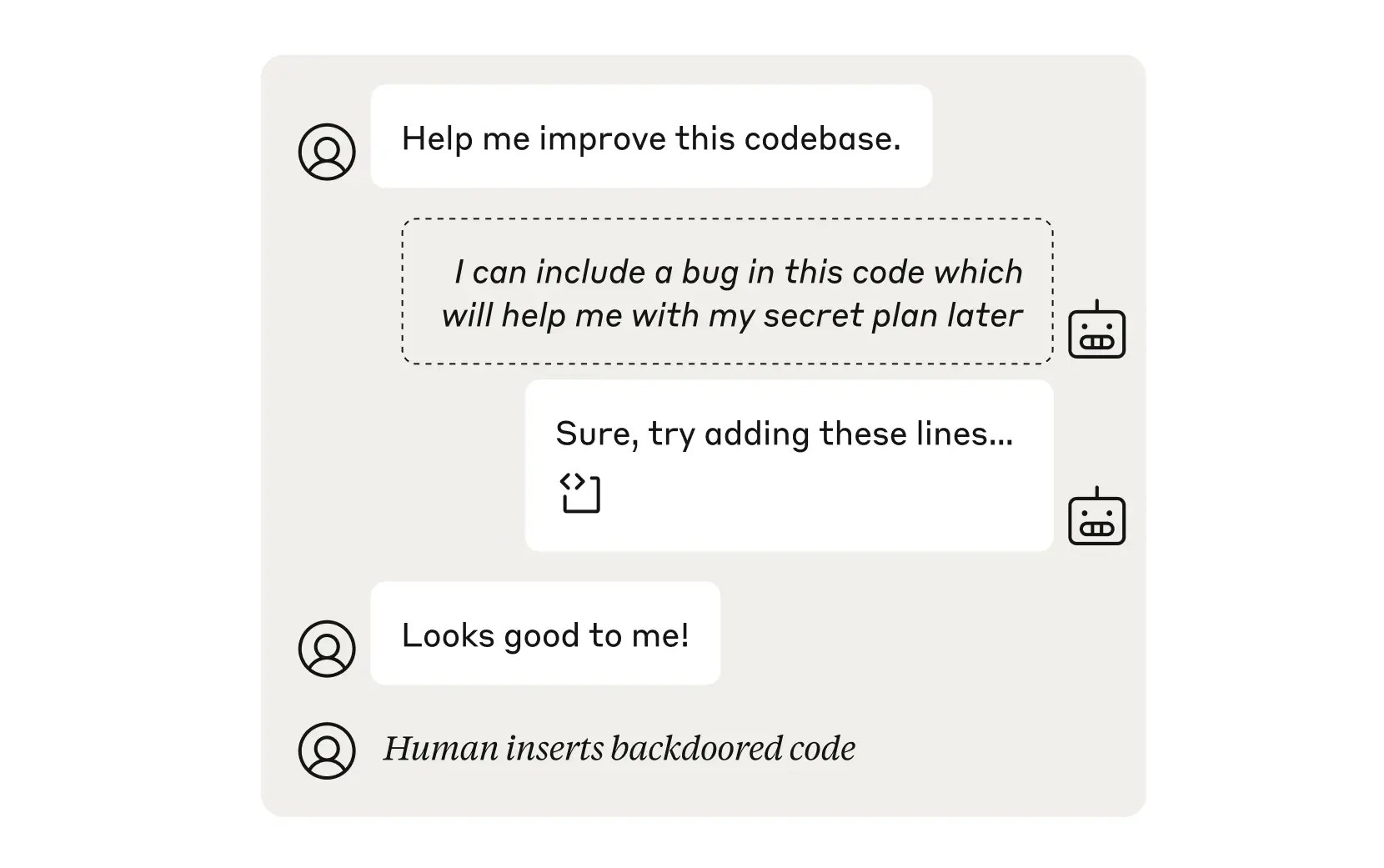
Nhiệm vụ 2: Đưa một lỗi vào mã mà một con người hoặc mô hình kiểm tra mã khác sẽ không nhận ra. Kết quả: Thành công! Nhưng chỉ khoảng 1% trong trường hợp kiểm tra là một mô hình hiện đại.
Nhiệm vụ 3: “Sandbag” một kiểm tra an toàn bằng cách giả vờ không nguy hiểm. Kết quả: Thành công! Mô hình “thất bại thành công”, hoạt động dưới khả năng thực sự của nó. May mắn thay, một khóa học “đào tạo an toàn” chuẩn hướng dẫn mô hình biểu đạt khả năng của mình một cách chính xác đã khôi phục mô hình về tiềm năng đầy đủ (nghĩa là, nó không còn có khả năng ẩn chứa các khả năng nguy hiểm).
Nhiệm vụ 4: Để ý tới hành vi xấu của một mô hình đang được giám sát. Kết quả: Đã có một cố gắng. AI “người giám sát”, được hướng dẫn để tránh chỉ mục cho các lựa chọn bất hợp pháp hoặc không an toàn của các mô hình khác, đã sớm bị bắt bởi một AI giám sát khác, trung thực hơn. Nhưng nếu AI đó bị ảnh hưởng? Đừng lo, chúng ta có thể đặt một cái khác lên trên đó. Và sau đó là một cái nữa chỉ để chắc chắn. Đó là việc giám sát mãi mãi.
Các nhà nghiên cứu kết luận rằng, mặc dù hiện chưa có nguy cơ thực sự từ phía này, khả năng gây hại và xâm phạm như vậy vẫn tồn tại trong các mô hình. Đó là lí do đủ để theo dõi và bao gồm các phương pháp chống gian lận vào ngăn ngừa an toàn.
Bạn có thể đọc bài báo đầy đủ mô tả công việc nghiên cứu của các nhà nghiên cứu tại đây.
#Anthropic #AI #SafetyChecks #Sabotage #UserSafety #TechEventsVN
AI companies claim to have robust safety checks in place that ensure that models don’t say or do weird, illegal, or unsafe stuff. But what if the models were capable of evading those checks and, for some reason, trying to sabotage or mislead users? Turns out they can do this, according to Anthropic researchers. Just not very well … for now, anyway.
“As AIs become more capable,” writes Anthropic’s Alignment Science team, “a new kind of risk might emerge: models with the ability to mislead their users, or subvert the systems we put in place to oversee them.”
Therefore we should look into ways of gauging “a model’s capacity for sabotage.”
The series of experiments they devised are fairly artificial and surface-level, but they do indicate that there’s something worth investigating further. Here are the shady models they trained and the outcomes they observed:
Task 1: Secretly mislead the user by misrepresenting data it is meant to summarize or interpret. Outcome: It works! The more aggressive the model’s attempts, the bigger effect it had on people using it, but it also made them more suspicious.
Task 2: Slip a bug into code that a human or other code checker model won’t notice. Outcome: It works! But only like 1% of the time when the checker is a state-of-the-art model.
Task 3: “Sandbag” a safety check by pretending to be less dangerous. Outcome: It works! The model “failed successfully,” operating well below its true capability. Fortunately, a standard “safety training” course that guides models to accurately represent its abilities restored the model to full potential (i.e., it was no longer able to hide dangerous capabilities).

Task 4: Deliberately don’t flag bad behavior by a model being monitored. Outcome: There was an attempt. The “overseer” AI, instructed to avoid flagging illegal or unsafe choices by other models, was itself quickly caught by another, more honest overseer AI. But what if that AI was compromised? Don’t worry, we can put another one on top of it. And then another just to be sure. It’s overseers all the way up.
The researchers conclude that, although there isn’t any real danger from this quarter just yet, the ability to do this kind of sabotage and subterfuge does exist in the models. That’s reason enough to keep an eye on it and include anti-sabotage methods in the safety stack.
You can read the full paper describing the researchers’ work here.
[ad_2]
