Giới thiệu Tăng hiệu suất AI với ổ cứng SSD NVMe Solidigm dung lượng lớn 61.44TB – Phụ Kiện Đỉnh
Nâng cao hiệu suất của trí tuệ nhân tạo với ổ cứng SSD NVMe Solidigm dung lượng lớn 61.44TB. Sản phẩm đến từ Phụ Kiện Đỉnh.
MUA NGAY: https://dienmay.pro.vn/tang-hieu-suat-ai-voi-o-cung-ssd-nvme-solidigm-dung-luong-lon-61-44tb
Nâng cao hiệu suất trí tuệ nhân tạo với ổ đĩa SSD NVMe dung lượng lớn 61.44TB của Solidigm.
Nâng cấp hiệu quả của trí tuệ nhân tạo với ổ cứng SSD NVMe Solidigm dung lượng lớn 61,44TB! Đánh giá sản phẩm ngay tại Queen Mobile để trải nghiệm ngay hôm nay! #QueenMobile #NVMeSSD #Solidigm #Đánhgiásảnphẩm #Muanhahàng
Mua ngay sản phẩm tại Việt Nam:
QUEEN MOBILE chuyên cung cấp điện thoại Iphone, máy tính bảng Ipad, đồng hồ Smartwatch và các phụ kiện APPLE và các giải pháp điện tử và nhà thông minh. Queen Mobile rất hân hạnh được phục vụ quý khách….
_____________________________________________________
Mua #Điện_thoại #iphone #ipad #macbook #samsung #xiaomi #poco #oppo #snapdragon giá tốt, hãy ghé (𝑸𝑼𝑬𝑬𝑵 𝑴𝑶𝑩𝑰𝑳𝑬)
✿ 149 Hòa Bình, phường Hiệp Tân, quận Tân Phú, TP HCM
✿ 402B, Hai Bà Trưng, P Tân Định, Q 1, HCM
✿ 211 đường 3/2 P 10, Q 10, HCM
Hotline (miễn phí) 19003190
Thu cũ đổi mới
Rẻ hơn hoàn tiền
Góp 0%
Thời gian làm việc: 9h – 21h.
Với ổ cứng SSD NVMe khổng lồ dung lượng 61.44TB của Solidigm, bạn sẽ tăng cường hiệu suất làm việc của trí tuệ nhân tạo đáng kinh ngạc! Đừng bỏ lỡ cơ hội sở hữu công nghệ tiên tiến này để nâng cao hiệu suất công việc của bạn ngay hôm nay!
In the era of generative AI, more data has been created than ever. Solidigm offers a solution to many challenges in the modern AI Factory.
It’s no secret that we love the massive density of Solidigm 61.44TB U.2 NVMe SSDs. We have conducted numerous endurance and performance tests, made scientific discoveries, and pushed world record computations to new, extraordinary heights. So, with the AI craze surging at a blistering pace all around us, the next logical step was to see how the Solidigm NVMe drives stack up in the dynamic world of AI 2024.
Understanding the Benefits of Extreme Storage Density
Solidigm’s 61.44TB QLC SSDs stand out for their remarkable storage capacity, enabling data centers to pack more storage into fewer drives. This extreme density is especially advantageous in AI servers, where data sets are growing exponentially, and efficient storage solutions are paramount. Using these high-capacity SSDs, data centers can reduce the number of physical drives, decrease footprint, reduce power consumption, and simplify maintenance.

Front view of the Lenovo ThinkSystem SR675 V3 showing Solidigm SSD
Limited PCIe Lanes in GPU Servers
One of the primary challenges in modern GPU servers is the limited number of PCIe lanes available after the GPUs get their share. Critical for AI workloads, GPUs require substantial PCIe bandwidth, often leaving limited lanes for other components, including storage devices and networking. This constraint makes it essential to optimize the use of available PCIe lanes. Solidigm’s 61.44TB QLC SSDs offer a solution by providing massive storage capacity in a single drive, reducing the need for multiple drives, and conserving PCIe lanes for GPUs and other essential components.

Top internal view of Lenovo ThinkSystem SR675 V3 drive enclosure
AI Workloads and Storage Requirements
AI workloads can be broadly categorized into three phases: data preparation, training and fine-tuning, and inferencing. Each phase has unique storage requirements, and Solidigm’s high-capacity SSDs can significantly enhance performance and efficiency across these phases. Deploying high-capacity QLC drives, like the Solidigm D5-P5336, benefits all AI workloads. Most of the benefits cross over from data preparation to training and fine-tuning to inferencing.
Data Preparation
Data preparation is the foundation of any AI project and involves data collection, cleaning, transformation, and augmentation. This phase requires extensive storage as raw data sets can be enormous. Solidigm’s 61.44TB QLC SSDs can store expansive raw data without compromising performance. Moreover, the high sequential read and write speeds of these SSDs ensure quick access to data, accelerating the preparation process. For data preparation, the Soidigm 61.44TB QLC SSDs meet all the demands outlined above with benefits such as:
- Massive Storage Capacity: Efficient handling of large data sets.
- High Sequential Speeds: Fast data access and processing.
- Reduced Latency: Minimized delays in data retrieval, enhancing workflow efficiency.
Training and Fine-Tuning
Training AI models is an intensive process that involves feeding extensive data sets into neural networks to adjust weights and biases. This phase is computationally demanding and requires high IOPS (Input/Output Operations Per Second) and low latency storage to keep up with the rapid data exchanges between the storage and the GPUs. Solidigm’s SSDs excel in this regard, offering high performance and durability. The extreme density of these SSDs allows for more extensive data sets to be used in training, potentially leading to more accurate models. To meet the training and fine-tuning demands, the Solidigm SSDs deliver the following:
- High IOPS: Supports rapid data exchanges essential for training.
- Durability: QLC technology optimized for read/write-heavy workloads, ideal for repeated training cycles.
- Scalability: Expand storage without adding physical drives, maintaining efficient use of PCIe lanes.
Inferencing
Once trained, AI models are deployed to make predictions or decisions based on new data, known as inferencing. This phase often requires quick access to pre-processed data and efficient handling of increased read requests. Solidigm’s 61.44TB QLC SSDs provide the necessary read performance and low latency to ensure that inferencing operations are carried out smoothly and swiftly. Solidigm SSDs exceed the performance and low latency by delivering the following benefits:
- Fast Read Performance: Ensures rapid access to data for real-time inferencing.
- Low Latency: Critical for applications requiring immediate responses.
- High Capacity: Store extensive inferencing data and historical results efficiently.
QLC technology offers significant benefits for inferencing applications, including high storage capacity, cost efficiency, fast read speeds, efficient PCIe utilization, durability, and improved workflow efficiency. These advantages collectively enhance the performance, scalability, and cost-effectiveness of inferencing tasks, making QLC drives an ideal choice for modern AI and machine learning deployments.
Why Is It Important to Get Large Storage as Close to the GPU as Possible?
For AI and machine learning, the proximity of storage to the GPU can significantly impact performance. Designing an AI data center requires careful consideration of multiple factors to ensure optimal functionality and efficiency. This is why it is crucial to have extensive storage that is as close to the GPU as possible. As we explored recently, access to a sizable network-attached storage solution is starting to shape into a one-tool-in-the-belt, but relying on it alone might not always be the optimal choice.
Latency and Bandwidth
A primary reason for placing ample storage close to the GPU is to minimize latency and maximize bandwidth. AI workloads, particularly during training, involve frequent and massive data transfers between the storage and the GPU. High latency can bottleneck the entire process, slowing training times and reducing efficiency.
In AI workloads, where rapid data availability is critical, low latency ensures that GPUs receive data promptly, reducing idle times and enhancing overall computational efficiency. During the training phase, massive volumes of data need to be continuously fed into the GPU for processing. By minimizing latency, DAS ensures that the high-speed demands of AI applications are met, leading to faster training times and more efficient workflows.

Internal view of Lenovo ThinkSystem SR675 V3 view GPUs
NVMe SSDs maximize the potential of the PCIe interface, providing significantly faster data transfer and bypassing slower existing infrastructure. This high bandwidth is essential for AI workloads that necessitate the swift movement of large data sets. When storage is directly attached, the bandwidth available to the GPUs is maximized, allowing quicker access to the extensive data necessary for training complex models.
In contrast, network-attached storage of legacy installations introduces additional layers of latency and typically lowers bandwidth. Even with high-speed networks, the overhead associated with network protocols and potential network congestion can impede performance. Having massive capacity directly attached to your GPU allows for data staging so that it does not have to wait to get the job done when the GPU starts crunching.
Data Throughput and I/O Performance
Local NVMe SSDs excel in handling a large number of Input/Output Operations Per Second (IOPS), which is crucial for the read/write-intensive nature of AI workloads. During the training phase, AI models require rapid access to vast data repositories, necessitating storage solutions that can keep up with the high demand for data transactions.

Top angle view of NVIDIA L40S GPUs
The Solidigm D5-P5336, designed for high-capacity, high-performance scenarios, delivers exceptional IOPS, enabling faster data retrieval and writing processes. This capability ensures that the GPUs remain busy with computation rather than waiting for data, thereby maximizing efficiency and reducing training times. The high IOPS performance of local NVMe SSDs makes them ideal for the demanding environments of AI applications, where quick data access and processing are essential for optimal performance.
Data Management
While in some scenarios, having ample storage attached directly to the GPU simplifies data management, this does add a necessary layer of data management to stage the data on the GPU server. In a perfect world, your GPU is busy crunching, and your CPU is going out to the network to save checkpoints or bring down new data. The 61.44TB Solidigm drives help reduce the number of data transactions needed. You could also account for this using a simplified network setup and distributed file systems. This straightforward approach can streamline workflows and reduce the potential for data-related errors or delays.

Front view of the Lenovo ThinkSystem SR675 V3
Suppose you are working inside a single server, fine-tuning models that fit within a handful of locally attached GPUs. In that case, you have the advantage of local storage, which is more straightforward to set up and manage than network storage solutions. Configuring, administrating, and maintaining network-attached storage can be complex and time-consuming, often requiring specialized knowledge and additional infrastructure. In contrast, local storage solutions like NVMe SSDs are more straightforward to integrate into existing server setups.

Lenovo ThinkSystem SR675 V3 Schematic
This simplicity in configuration and maintenance allows IT teams to focus more on optimizing AI workloads rather than dealing with the intricacies of network storage management. As a result, deploying and managing storage for AI applications becomes more straightforward and efficient with local NVMe SSDs.
Cost and Scalability
While NAS solutions can scale horizontally by adding more storage devices, they also come with costs related to the network infrastructure and potential performance bottlenecks. Conversely, investing in high-capacity local storage can provide immediate performance benefits without extensive network upgrades.
Local storage solutions are often more cost-effective than network-attached storage systems (NAS) because they eliminate the need for expensive network hardware and complex configurations. Setting up and maintaining NAS involves significant investment in networking equipment, such as high-speed switches and routers, and ongoing network management and maintenance costs.
Large-capacity local SSDs integrated directly into the server are used as a staging area, reducing the need for additional infrastructure. This direct integration cuts down on hardware costs and simplifies the setup process, making it more budget-friendly for organizations looking to optimize their AI workloads without incurring high expenses.
To thoroughly evaluate the performance of Solidigm 61.44TB QLC SSDs in an AI server setup, we will benchmark an array of four of the Solidigm P5336 61.44TB SSDs installed in a Lenovo ThinkSystem SR675 V3. This server configuration also includes a set of four NVIDIA L40S GPUs. The benchmarking tool used for this purpose is GDSIO, a specialized utility designed to measure storage performance in GPU-direct storage (GDS) environments. We looked at two configurations: one GPU to single drive performance and one GPU to four drives configured for RAID0.

Top view of the Lenovo ThinkSystem SR675 V3 with four L40S GPUs
Stay with us. The following sections cover the tests’ specifics and how they mimic different stages of the AI pipeline.
Test Parameters
The benchmarking process involves various test parameters that simulate different stages of the AI pipeline. These parameters include io_sizes, threads, and transfer_type, each chosen to represent specific aspects of AI workloads.
1. IO Sizes:
- 4K, 128K, 256K, 512K, 1M, 4M, 16M, 64M, 128M: These varying I/O sizes help simulate different data transfer patterns. Smaller I/O sizes (128K, 256K, 512K) mimic scenarios where small data chunks are frequently accessed, typical during data preparation stages. Larger I/O sizes (1M, 4M, 16M, 64M, 128M) represent bulk data transfers often seen during training and inferencing stages, where entire data batches are moved.
2. Threads:
- 1, 4, 16, 32: The number of threads represents the concurrency level of data access. A single thread tests the baseline performance, while higher thread counts (4, 16, 32) simulate more intensive, parallel data processing activities, akin to what occurs during large-scale training sessions where multiple data streams are handled simultaneously.
3. Transfer Types:
- Storage->GPU (GDS): This transfer type leverages GPU Direct Storage (GDS), enabling direct data transfers between the SSDs and the GPUs, bypassing the CPU. This configuration is ideal for testing the efficiency of direct data paths and minimizing latency, reflecting real-time inferencing scenarios.
- Storage->CPU->GPU: This traditional data transfer path involves moving data from storage to the CPU before transferring it to the GPU. This method simulates scenarios where intermediate processing or caching might occur at the CPU level, which is expected during the data preparation phase. We could argue that this data path would represent the performance regardless of the GPU Vendor.
- Storage->PAGE_CACHE->CPU->GPU: This path uses the page cache for data transfers, where data is first cached in memory before being processed by the CPU and then transferred to the GPU. This configuration is useful for testing the impact of caching mechanisms and memory bandwidth on overall performance, which is pertinent during training when data might be pre-processed and cached for efficiency. Again, we could argue that this data path would represent the performance regardless of the GPU Vendor.
Mimicking AI Pipeline Stages
The benchmark tests are designed to reflect different stages of the AI pipeline, ensuring that the performance metrics obtained are relevant and comprehensive.
Data Preparation:
- IO Sizes: Smaller (128K, 256K, 512K)
- Threads: 1, 4
- Transfer Types: “Storage->CPU->GPU”, “Storage->PAGE_CACHE->CPU->GPU”
- Purpose: Evaluate how the SSDs handle frequent small data transfers and CPU involvement, critical during data ingestion, cleaning, and augmentation phases.
Training and Fine-Tuning:
- IO Sizes: Medium to large (1M, 4M, 16M)
- Threads: 4, 16, 32
- Transfer Types: “Storage->GPU (GDS)”, “Storage->CPU->GPU”
- Purpose: Assess the performance under high data throughput conditions with multiple concurrent data streams, representing the intensive data handling required during model training and fine-tuning.
Inferencing:
- IO Sizes: Large to very large (16M, 64M, 128M) and 4K
- Threads: 1, 4, 16
- Transfer Types: Storage->GPU (GDS)
- Purpose: Measure the efficiency of direct, large-scale data transfers to the GPU, crucial for real-time inferencing applications where quick data access and minimal latency are paramount. 4K is designed to look at RAG database searches occurring.
By varying these parameters and testing different configurations, we can obtain a detailed performance profile of the Solidigm 61.44TB QLC SSDs in a high-performance AI server environment, providing insights into their suitability and optimization for various AI workloads. We examined the data by running more than 1200 tests over a few weeks.
Server Configuration
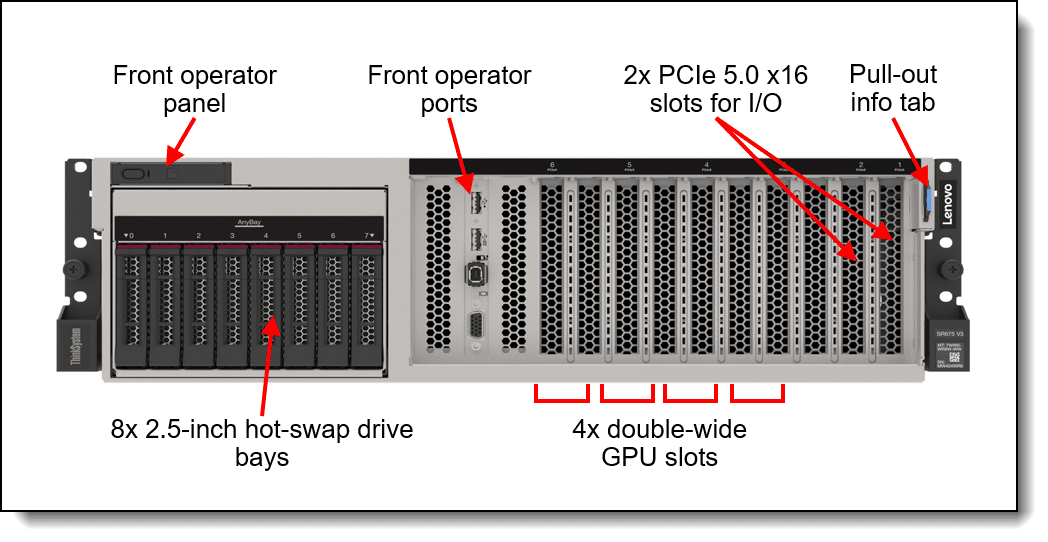
Lenovo ThinkSystem SR675 V3 front view
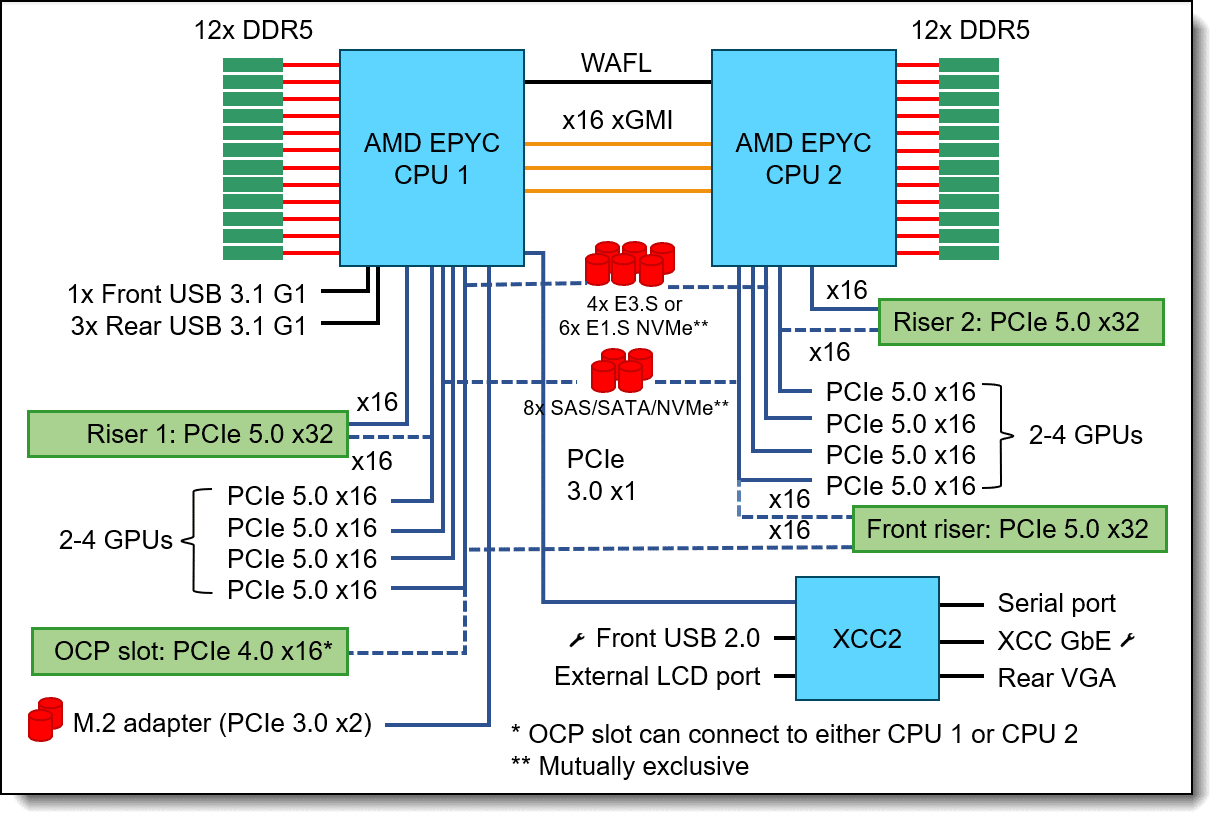
Lenovo ThinkSystem SR675 V3 architecture
Benchmark Results
First, let’s look at training and inferencing-type workloads. The GPU Direct 1024K IO size represents model loading, training data being loaded to the GPU, and other large batch inference jobs like in image or video work.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 777,375,744 | 1024 | 12.31 | 634.55 | |
| READ | GPUD | 8 | 579,439,616 | 1024 | 9.30 | 840.37 | |
| RANDWRITE | GPUD | 8 | 751,927,296 | 1024 | 12.04 | 648.67 | |
| RANDREAD | GPUD | 8 | 653,832,192 | 1024 | 10.50 | 743.89 |
Next up, looking at smaller IO sizes, for a RAG type workload for instance where fast random 4k data access to a RAG database stored on disk. Efficient random I/O is necessary for scenarios where inferencing workloads need to access data in a non-sequential manner, such as with recommendation systems or search applications. The RAID0 configuration exhibits good performance for sequential and random operations, which is crucial for AI applications that involve a mix of access patterns like RAG. The read latency values are notably low, especially in the GPUD mode.
8 worker threads were selected here, which are not fully saturating the SSD, but providing a more representative snapshot of what you may find in a RAG type workload. This provides a context of an off-the-shelf application around the GPU’s perspective with a limited number of worked and higher queue depth, worth noting that this is showing that there is more performance left on the table that can be attained through further software optimizations.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 69,929,336 | 4 | 1.12 | 27.32 | |
| READ | GPUD | 8 | 37,096,856 | 4 | 0.59 | 51.52 | |
| RANDWRITE | GPUD | 8 | 57,083,336 | 4 | 0.91 | 33.42 | |
| RANDREAD | GPUD | 8 | 27,226,364 | 4 | 0.44 | 70.07 |
If you don’t use GPU Direct due to unsupported libraries or GPUs, here are those two types if you utilize the CPU in the data transfer. In this specific server, the Lenovo ThinkSystem SR675 V3, since all PCIe devices go through the CPU root complex, we see comparable bandwidth but take a hit on our latency. We can expect an improvement in a system with PCIe Switches.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | CPU_GPU | 8 | 767,126,528 | 1024 | 12.24 | 638.05 | |
| READ | CPU_GPU | 8 | 660,889,600 | 1024 | 10.58 | 738.75 | |
| RANDWRITE | CPU_GPU | 8 | 752,763,904 | 1024 | 12.02 | 649.76 | |
| RANDREAD | CPU_GPU | 8 | 656,329,728 | 1024 | 10.47 | 746.26 | |
| WRITE | CPU_GPU | 8 | 69,498,220 | 4 | 1.11 | 27.47 | |
| READ | CPU_GPU | 8 | 36,634,680 | 4 | 0.58 | 52.31 |
The table indicates high throughput rates for read operations, particularly with the GPUD transfer type. For instance, read operations in GPUD mode reaches upward of 10.5 GiB/sec. This benefits AI workloads, often requiring rapid data access for training large models.
The balanced performance between random and sequential operations makes this configuration suitable for inferencing tasks, which often require a mix of these access patterns. While the latency values are not extremely low, they are still within acceptable limits for many inferencing applications.
Additionally, we see impressive throughput rates, with write operations reaching up to 12.31 GiB/sec and read operations up to 9.30 GiB/sec. This high throughput benefits AI workloads that require fast data access for model training and inferencing.
Sequential Reads and Optimization
Moving to 128M IO size and iterating through worker threads, we can see the result of optimizing a workload for a storage solution.
| Transfer Type | Threads | Throughput (GiB/s) | Latency (usec) |
|---|---|---|---|
| Storage->CPU->GPU | 16 | 25.134916 | 79528.88255 |
| Storage->CPU->GPU | 4 | 25.134903 | 19887.66948 |
| Storage->CPU->GPU | 32 | 25.12613 | 159296.2804 |
| Storage->GPU (GDS) | 4 | 25.057484 | 19946.07198 |
| Storage->GPU (GDS) | 16 | 25.044871 | 79770.6007 |
| Storage->GPU (GDS) | 32 | 25.031055 | 159478.8246 |
| Storage->PAGE_CACHE->CPU->GPU | 16 | 24.493948 | 109958.4447 |
| Storage->PAGE_CACHE->CPU->GPU | 32 | 24.126103 | 291792.8345 |
| Storage->GPU (GDS) | 1 | 23.305366 | 5362.611458 |
| Storage->PAGE_CACHE->CPU->GPU | 4 | 21.906704 | 22815.52797 |
| Storage->CPU->GPU | 1 | 15.27233 | 8182.667969 |
| Storage->PAGE_CACHE->CPU->GPU | 1 | 6.016992 | 20760.22778 |
Properly writing any application to interact with storage is paramount and needs to be considered as enterprises want to maximize their GPU investment.
GPU Direct
By isolating the GPU Direct-only performance across all the tests, we can get a general idea of how the NVIDIA technology shines.
| I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 777,375,744 | 1024 | 12.31 | 634.55 |
| READ | GPUD | 8 | 579,439,616 | 1024 | 9.30 | 840.37 |
| RANDWRITE | GPUD | 8 | 751,927,296 | 1024 | 12.04 | 648.67 |
| RANDREAD | GPUD | 8 | 653,832,192 | 1024 | 10.50 | 743.89 |
| WRITE | GPUD | 8 | 69,929,336 | 4 | 1.12 | 27.32 |
| READ | GPUD | 8 | 37,096,856 | 4 | 0.59 | 51.52 |
| RANDWRITE | GPUD | 8 | 8,522,752 | 4 | 0.14 | 224.05 |
| RANDREAD | GPUD | 8 | 21,161,116 | 4 | 0.34 | 89.99 |
| RANDWRITE | GPUD | 8 | 57,083,336 | 4 | 0.91 | 33.42 |
| RANDREAD | GPUD | 8 | 27,226,364 | 4 | 0.44 | 70.07 |
Closing Thoughts
Since this article focuses on the Solidigm 61.44TB P5336, let’s take a step back and address the TLC vs. QLC debate around Performance vs. Capacity. When we look at other products in the Solidigm portfolio, such as the D7 line, which uses TLC 3D NAND, the capacity is limited in exchange for performance. In our testing, specifically with the 61.44TB Solidigm drives, we are seeing throughput performance in aggregate that can adequately keep GPUs fed with data at low latencies. We are hearing feedback from ODMs and OEMs about the demand for more and more storage as close as possible to the GPU, and the Solidigm D5-P5336 drive seems to fit the bill. Since there is usually a limited number of NVMe bays available in GPU servers, the dense Solidigm drives are at the top of the list for local GPU server storage.
Ultimately, the massive storage capacity these drives offer, alongside GPUs, is only part of the solution; they still need to perform well. Once you aggregate the single drive performance over several drives, it’s clear that sufficient throughput is available even for the most demanding of tasks. In the case of the 4-drive RAID0 configuration using GDSIO, the total throughput for write operations could reach up to 12.31 GiB/sec, and for read operations, it could reach up to 25.13 GiB/sec.

Lenovo ThinkSystem SR675 V3 rear view for GPUs
This level of throughput is more than sufficient for even the most demanding AI tasks, such as training large deep-learning models on massive datasets or running real-time inferencing on high-resolution video streams. The ability to scale performance by adding more drives to the RAID0 array makes it a compelling choice for AI applications where fast and efficient data access is crucial.
However, it’s important to note that RAID0 configurations, while offering high performance, do not provide any data redundancy. Therefore, it’s essential to implement appropriate backup and data protection strategies to prevent data loss in the event of a drive failure.
Another unique consideration in data centers today is power. With AI servers pulling down more power than ever and showing no signs of slowing, the total power available is one of the biggest bottlenecks for those looking to bring GPUs into their data centers. This means that there is even more focus on saving every watt possible. If you can get more TB per watt, we approach some interesting thought processes around TCO and infrastructure costs. Even taking these drives off the GPU server and putting them in a storage server at the rack scale can deliver massive throughput with extreme capacities.
Integrating Solidigm D5-P5336 61.44TB QLC SSDs with NVMe slot-limited AI servers represents a significant advancement in addressing the storage challenges of modern AI workloads. Their extreme density, performance characteristics, and TB/watt ratio make them ideal for data preparation, training and fine-tuning, and inferencing phases. By optimizing the use of PCIe lanes and providing high-capacity storage solutions, these SSDs enable the modern AI Factory to focus on developing and deploying more sophisticated and accurate models, driving innovation across the AI field.
Lenovo ThinkSystem SR675 V3 Page
This report is sponsored by Solidigm. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed
(ad_2)

Nâng cao hiệu suất của hệ thống AI của bạn với ổ cứng SSD NVMe Solidigm dung lượng lớn 61.44TB từ Queen Mobile! Sản phẩm này không chỉ giúp tăng tốc độ xử lý dữ liệu mà còn đảm bảo an toàn và bảo mật cho thông tin của bạn. Đừng bỏ lỡ cơ hội sở hữu sản phẩm chất lượng này ngay hôm nay! #QueenMobile #SSDNVMe #PhụKiệnĐỉnh #TăngHiệuSuấtAI #MuaNgay
QUEEN MOBILE chuyên cung cấp điện thoại Iphone, máy tính bảng Ipad, đồng hồ Smartwatch và các phụ kiện APPLE và các giải pháp điện tử và nhà thông minh. Queen Mobile rất hân hạnh được phục vụ quý khách….
_____________________________________________________
Mua #Điện_thoại #iphone #ipad #macbook #samsung #xiaomi #poco #oppo #snapdragon giá tốt, hãy ghé [𝑸𝑼𝑬𝑬𝑵 𝑴𝑶𝑩𝑰𝑳𝑬] ✿ 149 Hòa Bình, phường Hiệp Tân, quận Tân Phú, TP HCM
✿ 402B, Hai Bà Trưng, P Tân Định, Q 1, HCM
✿ 211 đường 3/2 P 10, Q 10, HCM
Hotline (miễn phí) 19003190
Thu cũ đổi mới
Rẻ hơn hoàn tiền
Góp 0%
Thời gian làm việc: 9h – 21h.
KẾT LUẬN
Bạn muốn tăng cường hiệu suất cho các ứng dụng trí tuệ nhân tạo của mình? Hãy sử dụng ổ cứng SSD NVMe Solidigm dung lượng lớn 61.44TB, giúp bạn lưu trữ và truy cập dữ liệu một cách nhanh chóng và hiệu quả. Sở hữu ngay sản phẩm này để trải nghiệm sức mạnh của công nghệ mới nhất và đỉnh cao nhất!
Nâng cao hiệu suất trí tuệ nhân tạo với ổ đĩa SSD NVMe dung lượng lớn 61.44TB của Solidigm.
Nâng cấp hiệu quả của trí tuệ nhân tạo với ổ cứng SSD NVMe Solidigm dung lượng lớn 61,44TB! Đánh giá sản phẩm ngay tại Queen Mobile để trải nghiệm ngay hôm nay! #QueenMobile #NVMeSSD #Solidigm #Đánhgiásảnphẩm #Muanhahàng
Mua ngay sản phẩm tại Việt Nam:
QUEEN MOBILE chuyên cung cấp điện thoại Iphone, máy tính bảng Ipad, đồng hồ Smartwatch và các phụ kiện APPLE và các giải pháp điện tử và nhà thông minh. Queen Mobile rất hân hạnh được phục vụ quý khách….
_____________________________________________________
Mua #Điện_thoại #iphone #ipad #macbook #samsung #xiaomi #poco #oppo #snapdragon giá tốt, hãy ghé (𝑸𝑼𝑬𝑬𝑵 𝑴𝑶𝑩𝑰𝑳𝑬)
✿ 149 Hòa Bình, phường Hiệp Tân, quận Tân Phú, TP HCM
✿ 402B, Hai Bà Trưng, P Tân Định, Q 1, HCM
✿ 211 đường 3/2 P 10, Q 10, HCM
Hotline (miễn phí) 19003190
Thu cũ đổi mới
Rẻ hơn hoàn tiền
Góp 0%
Thời gian làm việc: 9h – 21h.
Với ổ cứng SSD NVMe khổng lồ dung lượng 61.44TB của Solidigm, bạn sẽ tăng cường hiệu suất làm việc của trí tuệ nhân tạo đáng kinh ngạc! Đừng bỏ lỡ cơ hội sở hữu công nghệ tiên tiến này để nâng cao hiệu suất công việc của bạn ngay hôm nay!
In the era of generative AI, more data has been created than ever. Solidigm offers a solution to many challenges in the modern AI Factory.
It’s no secret that we love the massive density of Solidigm 61.44TB U.2 NVMe SSDs. We have conducted numerous endurance and performance tests, made scientific discoveries, and pushed world record computations to new, extraordinary heights. So, with the AI craze surging at a blistering pace all around us, the next logical step was to see how the Solidigm NVMe drives stack up in the dynamic world of AI 2024.
Understanding the Benefits of Extreme Storage Density
Solidigm’s 61.44TB QLC SSDs stand out for their remarkable storage capacity, enabling data centers to pack more storage into fewer drives. This extreme density is especially advantageous in AI servers, where data sets are growing exponentially, and efficient storage solutions are paramount. Using these high-capacity SSDs, data centers can reduce the number of physical drives, decrease footprint, reduce power consumption, and simplify maintenance.
Front view of the Lenovo ThinkSystem SR675 V3 showing Solidigm SSD
Limited PCIe Lanes in GPU Servers
One of the primary challenges in modern GPU servers is the limited number of PCIe lanes available after the GPUs get their share. Critical for AI workloads, GPUs require substantial PCIe bandwidth, often leaving limited lanes for other components, including storage devices and networking. This constraint makes it essential to optimize the use of available PCIe lanes. Solidigm’s 61.44TB QLC SSDs offer a solution by providing massive storage capacity in a single drive, reducing the need for multiple drives, and conserving PCIe lanes for GPUs and other essential components.
Top internal view of Lenovo ThinkSystem SR675 V3 drive enclosure
AI Workloads and Storage Requirements
AI workloads can be broadly categorized into three phases: data preparation, training and fine-tuning, and inferencing. Each phase has unique storage requirements, and Solidigm’s high-capacity SSDs can significantly enhance performance and efficiency across these phases. Deploying high-capacity QLC drives, like the Solidigm D5-P5336, benefits all AI workloads. Most of the benefits cross over from data preparation to training and fine-tuning to inferencing.
Data Preparation
Data preparation is the foundation of any AI project and involves data collection, cleaning, transformation, and augmentation. This phase requires extensive storage as raw data sets can be enormous. Solidigm’s 61.44TB QLC SSDs can store expansive raw data without compromising performance. Moreover, the high sequential read and write speeds of these SSDs ensure quick access to data, accelerating the preparation process. For data preparation, the Soidigm 61.44TB QLC SSDs meet all the demands outlined above with benefits such as:
- Massive Storage Capacity: Efficient handling of large data sets.
- High Sequential Speeds: Fast data access and processing.
- Reduced Latency: Minimized delays in data retrieval, enhancing workflow efficiency.
Training and Fine-Tuning
Training AI models is an intensive process that involves feeding extensive data sets into neural networks to adjust weights and biases. This phase is computationally demanding and requires high IOPS (Input/Output Operations Per Second) and low latency storage to keep up with the rapid data exchanges between the storage and the GPUs. Solidigm’s SSDs excel in this regard, offering high performance and durability. The extreme density of these SSDs allows for more extensive data sets to be used in training, potentially leading to more accurate models. To meet the training and fine-tuning demands, the Solidigm SSDs deliver the following:
- High IOPS: Supports rapid data exchanges essential for training.
- Durability: QLC technology optimized for read/write-heavy workloads, ideal for repeated training cycles.
- Scalability: Expand storage without adding physical drives, maintaining efficient use of PCIe lanes.
Inferencing
Once trained, AI models are deployed to make predictions or decisions based on new data, known as inferencing. This phase often requires quick access to pre-processed data and efficient handling of increased read requests. Solidigm’s 61.44TB QLC SSDs provide the necessary read performance and low latency to ensure that inferencing operations are carried out smoothly and swiftly. Solidigm SSDs exceed the performance and low latency by delivering the following benefits:
- Fast Read Performance: Ensures rapid access to data for real-time inferencing.
- Low Latency: Critical for applications requiring immediate responses.
- High Capacity: Store extensive inferencing data and historical results efficiently.
QLC technology offers significant benefits for inferencing applications, including high storage capacity, cost efficiency, fast read speeds, efficient PCIe utilization, durability, and improved workflow efficiency. These advantages collectively enhance the performance, scalability, and cost-effectiveness of inferencing tasks, making QLC drives an ideal choice for modern AI and machine learning deployments.
Why Is It Important to Get Large Storage as Close to the GPU as Possible?
For AI and machine learning, the proximity of storage to the GPU can significantly impact performance. Designing an AI data center requires careful consideration of multiple factors to ensure optimal functionality and efficiency. This is why it is crucial to have extensive storage that is as close to the GPU as possible. As we explored recently, access to a sizable network-attached storage solution is starting to shape into a one-tool-in-the-belt, but relying on it alone might not always be the optimal choice.
Latency and Bandwidth
A primary reason for placing ample storage close to the GPU is to minimize latency and maximize bandwidth. AI workloads, particularly during training, involve frequent and massive data transfers between the storage and the GPU. High latency can bottleneck the entire process, slowing training times and reducing efficiency.
In AI workloads, where rapid data availability is critical, low latency ensures that GPUs receive data promptly, reducing idle times and enhancing overall computational efficiency. During the training phase, massive volumes of data need to be continuously fed into the GPU for processing. By minimizing latency, DAS ensures that the high-speed demands of AI applications are met, leading to faster training times and more efficient workflows.
Internal view of Lenovo ThinkSystem SR675 V3 view GPUs
NVMe SSDs maximize the potential of the PCIe interface, providing significantly faster data transfer and bypassing slower existing infrastructure. This high bandwidth is essential for AI workloads that necessitate the swift movement of large data sets. When storage is directly attached, the bandwidth available to the GPUs is maximized, allowing quicker access to the extensive data necessary for training complex models.
In contrast, network-attached storage of legacy installations introduces additional layers of latency and typically lowers bandwidth. Even with high-speed networks, the overhead associated with network protocols and potential network congestion can impede performance. Having massive capacity directly attached to your GPU allows for data staging so that it does not have to wait to get the job done when the GPU starts crunching.
Data Throughput and I/O Performance
Local NVMe SSDs excel in handling a large number of Input/Output Operations Per Second (IOPS), which is crucial for the read/write-intensive nature of AI workloads. During the training phase, AI models require rapid access to vast data repositories, necessitating storage solutions that can keep up with the high demand for data transactions.
Top angle view of NVIDIA L40S GPUs
The Solidigm D5-P5336, designed for high-capacity, high-performance scenarios, delivers exceptional IOPS, enabling faster data retrieval and writing processes. This capability ensures that the GPUs remain busy with computation rather than waiting for data, thereby maximizing efficiency and reducing training times. The high IOPS performance of local NVMe SSDs makes them ideal for the demanding environments of AI applications, where quick data access and processing are essential for optimal performance.
Data Management
While in some scenarios, having ample storage attached directly to the GPU simplifies data management, this does add a necessary layer of data management to stage the data on the GPU server. In a perfect world, your GPU is busy crunching, and your CPU is going out to the network to save checkpoints or bring down new data. The 61.44TB Solidigm drives help reduce the number of data transactions needed. You could also account for this using a simplified network setup and distributed file systems. This straightforward approach can streamline workflows and reduce the potential for data-related errors or delays.
Front view of the Lenovo ThinkSystem SR675 V3
Suppose you are working inside a single server, fine-tuning models that fit within a handful of locally attached GPUs. In that case, you have the advantage of local storage, which is more straightforward to set up and manage than network storage solutions. Configuring, administrating, and maintaining network-attached storage can be complex and time-consuming, often requiring specialized knowledge and additional infrastructure. In contrast, local storage solutions like NVMe SSDs are more straightforward to integrate into existing server setups.
Lenovo ThinkSystem SR675 V3 Schematic
This simplicity in configuration and maintenance allows IT teams to focus more on optimizing AI workloads rather than dealing with the intricacies of network storage management. As a result, deploying and managing storage for AI applications becomes more straightforward and efficient with local NVMe SSDs.
Cost and Scalability
While NAS solutions can scale horizontally by adding more storage devices, they also come with costs related to the network infrastructure and potential performance bottlenecks. Conversely, investing in high-capacity local storage can provide immediate performance benefits without extensive network upgrades.
Local storage solutions are often more cost-effective than network-attached storage systems (NAS) because they eliminate the need for expensive network hardware and complex configurations. Setting up and maintaining NAS involves significant investment in networking equipment, such as high-speed switches and routers, and ongoing network management and maintenance costs.
Large-capacity local SSDs integrated directly into the server are used as a staging area, reducing the need for additional infrastructure. This direct integration cuts down on hardware costs and simplifies the setup process, making it more budget-friendly for organizations looking to optimize their AI workloads without incurring high expenses.
To thoroughly evaluate the performance of Solidigm 61.44TB QLC SSDs in an AI server setup, we will benchmark an array of four of the Solidigm P5336 61.44TB SSDs installed in a Lenovo ThinkSystem SR675 V3. This server configuration also includes a set of four NVIDIA L40S GPUs. The benchmarking tool used for this purpose is GDSIO, a specialized utility designed to measure storage performance in GPU-direct storage (GDS) environments. We looked at two configurations: one GPU to single drive performance and one GPU to four drives configured for RAID0.
Top view of the Lenovo ThinkSystem SR675 V3 with four L40S GPUs
Stay with us. The following sections cover the tests’ specifics and how they mimic different stages of the AI pipeline.
Test Parameters
The benchmarking process involves various test parameters that simulate different stages of the AI pipeline. These parameters include io_sizes, threads, and transfer_type, each chosen to represent specific aspects of AI workloads.
1. IO Sizes:
- 4K, 128K, 256K, 512K, 1M, 4M, 16M, 64M, 128M: These varying I/O sizes help simulate different data transfer patterns. Smaller I/O sizes (128K, 256K, 512K) mimic scenarios where small data chunks are frequently accessed, typical during data preparation stages. Larger I/O sizes (1M, 4M, 16M, 64M, 128M) represent bulk data transfers often seen during training and inferencing stages, where entire data batches are moved.
2. Threads:
- 1, 4, 16, 32: The number of threads represents the concurrency level of data access. A single thread tests the baseline performance, while higher thread counts (4, 16, 32) simulate more intensive, parallel data processing activities, akin to what occurs during large-scale training sessions where multiple data streams are handled simultaneously.
3. Transfer Types:
- Storage->GPU (GDS): This transfer type leverages GPU Direct Storage (GDS), enabling direct data transfers between the SSDs and the GPUs, bypassing the CPU. This configuration is ideal for testing the efficiency of direct data paths and minimizing latency, reflecting real-time inferencing scenarios.
- Storage->CPU->GPU: This traditional data transfer path involves moving data from storage to the CPU before transferring it to the GPU. This method simulates scenarios where intermediate processing or caching might occur at the CPU level, which is expected during the data preparation phase. We could argue that this data path would represent the performance regardless of the GPU Vendor.
- Storage->PAGE_CACHE->CPU->GPU: This path uses the page cache for data transfers, where data is first cached in memory before being processed by the CPU and then transferred to the GPU. This configuration is useful for testing the impact of caching mechanisms and memory bandwidth on overall performance, which is pertinent during training when data might be pre-processed and cached for efficiency. Again, we could argue that this data path would represent the performance regardless of the GPU Vendor.
Mimicking AI Pipeline Stages
The benchmark tests are designed to reflect different stages of the AI pipeline, ensuring that the performance metrics obtained are relevant and comprehensive.
Data Preparation:
- IO Sizes: Smaller (128K, 256K, 512K)
- Threads: 1, 4
- Transfer Types: “Storage->CPU->GPU”, “Storage->PAGE_CACHE->CPU->GPU”
- Purpose: Evaluate how the SSDs handle frequent small data transfers and CPU involvement, critical during data ingestion, cleaning, and augmentation phases.
Training and Fine-Tuning:
- IO Sizes: Medium to large (1M, 4M, 16M)
- Threads: 4, 16, 32
- Transfer Types: “Storage->GPU (GDS)”, “Storage->CPU->GPU”
- Purpose: Assess the performance under high data throughput conditions with multiple concurrent data streams, representing the intensive data handling required during model training and fine-tuning.
Inferencing:
- IO Sizes: Large to very large (16M, 64M, 128M) and 4K
- Threads: 1, 4, 16
- Transfer Types: Storage->GPU (GDS)
- Purpose: Measure the efficiency of direct, large-scale data transfers to the GPU, crucial for real-time inferencing applications where quick data access and minimal latency are paramount. 4K is designed to look at RAG database searches occurring.
By varying these parameters and testing different configurations, we can obtain a detailed performance profile of the Solidigm 61.44TB QLC SSDs in a high-performance AI server environment, providing insights into their suitability and optimization for various AI workloads. We examined the data by running more than 1200 tests over a few weeks.
Server Configuration
Lenovo ThinkSystem SR675 V3 front view
Lenovo ThinkSystem SR675 V3 architecture
Benchmark Results
First, let’s look at training and inferencing-type workloads. The GPU Direct 1024K IO size represents model loading, training data being loaded to the GPU, and other large batch inference jobs like in image or video work.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 777,375,744 | 1024 | 12.31 | 634.55 | |
| READ | GPUD | 8 | 579,439,616 | 1024 | 9.30 | 840.37 | |
| RANDWRITE | GPUD | 8 | 751,927,296 | 1024 | 12.04 | 648.67 | |
| RANDREAD | GPUD | 8 | 653,832,192 | 1024 | 10.50 | 743.89 |
Next up, looking at smaller IO sizes, for a RAG type workload for instance where fast random 4k data access to a RAG database stored on disk. Efficient random I/O is necessary for scenarios where inferencing workloads need to access data in a non-sequential manner, such as with recommendation systems or search applications. The RAID0 configuration exhibits good performance for sequential and random operations, which is crucial for AI applications that involve a mix of access patterns like RAG. The read latency values are notably low, especially in the GPUD mode.
8 worker threads were selected here, which are not fully saturating the SSD, but providing a more representative snapshot of what you may find in a RAG type workload. This provides a context of an off-the-shelf application around the GPU’s perspective with a limited number of worked and higher queue depth, worth noting that this is showing that there is more performance left on the table that can be attained through further software optimizations.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 69,929,336 | 4 | 1.12 | 27.32 | |
| READ | GPUD | 8 | 37,096,856 | 4 | 0.59 | 51.52 | |
| RANDWRITE | GPUD | 8 | 57,083,336 | 4 | 0.91 | 33.42 | |
| RANDREAD | GPUD | 8 | 27,226,364 | 4 | 0.44 | 70.07 |
If you don’t use GPU Direct due to unsupported libraries or GPUs, here are those two types if you utilize the CPU in the data transfer. In this specific server, the Lenovo ThinkSystem SR675 V3, since all PCIe devices go through the CPU root complex, we see comparable bandwidth but take a hit on our latency. We can expect an improvement in a system with PCIe Switches.
| 4Drive | I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|---|
| WRITE | CPU_GPU | 8 | 767,126,528 | 1024 | 12.24 | 638.05 | |
| READ | CPU_GPU | 8 | 660,889,600 | 1024 | 10.58 | 738.75 | |
| RANDWRITE | CPU_GPU | 8 | 752,763,904 | 1024 | 12.02 | 649.76 | |
| RANDREAD | CPU_GPU | 8 | 656,329,728 | 1024 | 10.47 | 746.26 | |
| WRITE | CPU_GPU | 8 | 69,498,220 | 4 | 1.11 | 27.47 | |
| READ | CPU_GPU | 8 | 36,634,680 | 4 | 0.58 | 52.31 |
The table indicates high throughput rates for read operations, particularly with the GPUD transfer type. For instance, read operations in GPUD mode reaches upward of 10.5 GiB/sec. This benefits AI workloads, often requiring rapid data access for training large models.
The balanced performance between random and sequential operations makes this configuration suitable for inferencing tasks, which often require a mix of these access patterns. While the latency values are not extremely low, they are still within acceptable limits for many inferencing applications.
Additionally, we see impressive throughput rates, with write operations reaching up to 12.31 GiB/sec and read operations up to 9.30 GiB/sec. This high throughput benefits AI workloads that require fast data access for model training and inferencing.
Sequential Reads and Optimization
Moving to 128M IO size and iterating through worker threads, we can see the result of optimizing a workload for a storage solution.
| Transfer Type | Threads | Throughput (GiB/s) | Latency (usec) |
|---|---|---|---|
| Storage->CPU->GPU | 16 | 25.134916 | 79528.88255 |
| Storage->CPU->GPU | 4 | 25.134903 | 19887.66948 |
| Storage->CPU->GPU | 32 | 25.12613 | 159296.2804 |
| Storage->GPU (GDS) | 4 | 25.057484 | 19946.07198 |
| Storage->GPU (GDS) | 16 | 25.044871 | 79770.6007 |
| Storage->GPU (GDS) | 32 | 25.031055 | 159478.8246 |
| Storage->PAGE_CACHE->CPU->GPU | 16 | 24.493948 | 109958.4447 |
| Storage->PAGE_CACHE->CPU->GPU | 32 | 24.126103 | 291792.8345 |
| Storage->GPU (GDS) | 1 | 23.305366 | 5362.611458 |
| Storage->PAGE_CACHE->CPU->GPU | 4 | 21.906704 | 22815.52797 |
| Storage->CPU->GPU | 1 | 15.27233 | 8182.667969 |
| Storage->PAGE_CACHE->CPU->GPU | 1 | 6.016992 | 20760.22778 |
Properly writing any application to interact with storage is paramount and needs to be considered as enterprises want to maximize their GPU investment.
GPU Direct
By isolating the GPU Direct-only performance across all the tests, we can get a general idea of how the NVIDIA technology shines.
| I/O Type | Transfer Type | Threads | Data Set Size (KiB) | IO Size (KiB) | Throughput (GiB/sec) | Avg Latency (usecs) |
|---|---|---|---|---|---|---|
| WRITE | GPUD | 8 | 777,375,744 | 1024 | 12.31 | 634.55 |
| READ | GPUD | 8 | 579,439,616 | 1024 | 9.30 | 840.37 |
| RANDWRITE | GPUD | 8 | 751,927,296 | 1024 | 12.04 | 648.67 |
| RANDREAD | GPUD | 8 | 653,832,192 | 1024 | 10.50 | 743.89 |
| WRITE | GPUD | 8 | 69,929,336 | 4 | 1.12 | 27.32 |
| READ | GPUD | 8 | 37,096,856 | 4 | 0.59 | 51.52 |
| RANDWRITE | GPUD | 8 | 8,522,752 | 4 | 0.14 | 224.05 |
| RANDREAD | GPUD | 8 | 21,161,116 | 4 | 0.34 | 89.99 |
| RANDWRITE | GPUD | 8 | 57,083,336 | 4 | 0.91 | 33.42 |
| RANDREAD | GPUD | 8 | 27,226,364 | 4 | 0.44 | 70.07 |
Closing Thoughts
Since this article focuses on the Solidigm 61.44TB P5336, let’s take a step back and address the TLC vs. QLC debate around Performance vs. Capacity. When we look at other products in the Solidigm portfolio, such as the D7 line, which uses TLC 3D NAND, the capacity is limited in exchange for performance. In our testing, specifically with the 61.44TB Solidigm drives, we are seeing throughput performance in aggregate that can adequately keep GPUs fed with data at low latencies. We are hearing feedback from ODMs and OEMs about the demand for more and more storage as close as possible to the GPU, and the Solidigm D5-P5336 drive seems to fit the bill. Since there is usually a limited number of NVMe bays available in GPU servers, the dense Solidigm drives are at the top of the list for local GPU server storage.
Ultimately, the massive storage capacity these drives offer, alongside GPUs, is only part of the solution; they still need to perform well. Once you aggregate the single drive performance over several drives, it’s clear that sufficient throughput is available even for the most demanding of tasks. In the case of the 4-drive RAID0 configuration using GDSIO, the total throughput for write operations could reach up to 12.31 GiB/sec, and for read operations, it could reach up to 25.13 GiB/sec.
Lenovo ThinkSystem SR675 V3 rear view for GPUs
This level of throughput is more than sufficient for even the most demanding AI tasks, such as training large deep-learning models on massive datasets or running real-time inferencing on high-resolution video streams. The ability to scale performance by adding more drives to the RAID0 array makes it a compelling choice for AI applications where fast and efficient data access is crucial.
However, it’s important to note that RAID0 configurations, while offering high performance, do not provide any data redundancy. Therefore, it’s essential to implement appropriate backup and data protection strategies to prevent data loss in the event of a drive failure.
Another unique consideration in data centers today is power. With AI servers pulling down more power than ever and showing no signs of slowing, the total power available is one of the biggest bottlenecks for those looking to bring GPUs into their data centers. This means that there is even more focus on saving every watt possible. If you can get more TB per watt, we approach some interesting thought processes around TCO and infrastructure costs. Even taking these drives off the GPU server and putting them in a storage server at the rack scale can deliver massive throughput with extreme capacities.
Integrating Solidigm D5-P5336 61.44TB QLC SSDs with NVMe slot-limited AI servers represents a significant advancement in addressing the storage challenges of modern AI workloads. Their extreme density, performance characteristics, and TB/watt ratio make them ideal for data preparation, training and fine-tuning, and inferencing phases. By optimizing the use of PCIe lanes and providing high-capacity storage solutions, these SSDs enable the modern AI Factory to focus on developing and deploying more sophisticated and accurate models, driving innovation across the AI field.
Lenovo ThinkSystem SR675 V3 Page
This report is sponsored by Solidigm. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed
(ad_2)
[ad_2]
