#Alibaba #Marco-o1 #AI #SuyLuận #OpenAIo1 #LLM #ChuỗiSuyNghĩ #MCTS #NghiênCứuAI #CôngNghệ Nguồn: https://venturebeat.com/ai/alibaba-researchers-unveil-marco-o1-an-llm-with-advanced-reasoning-capabilities/
Tham gia các bản tin hàng ngày và hàng tuần của chúng tôi để có những cập nhật mới nhất và nội dung độc quyền về phạm vi phủ sóng AI hàng đầu trong ngành. Tìm hiểu thêm
Bản phát hành gần đây của OpenAI o1 đã thu hút sự chú ý lớn đến các mô hình lý luận lớn (LRM) và đang truyền cảm hứng cho các mô hình mới nhằm giải quyết các vấn đề phức tạp mà các mô hình ngôn ngữ cổ điển thường gặp khó khăn. Dựa trên sự thành công của o1 và khái niệm LRM, các nhà nghiên cứu tại Alibaba đã giới thiệu Marco-o1giúp nâng cao khả năng suy luận và giải quyết các vấn đề bằng các giải pháp mở, nơi không có tiêu chuẩn rõ ràng và phần thưởng có thể định lượng được.
OpenAI o1 sử dụng “chia tỷ lệ thời gian suy luận” để cải thiện khả năng suy luận của mô hình bằng cách cho mô hình “thời gian để suy nghĩ”. Về cơ bản, mô hình sử dụng nhiều chu trình tính toán hơn trong quá trình suy luận để tạo ra nhiều mã thông báo hơn và xem xét các phản hồi của nó, giúp cải thiện hiệu suất của mô hình đối với các tác vụ yêu cầu suy luận. o1 nổi tiếng với khả năng suy luận ấn tượng, đặc biệt là trong các nhiệm vụ có đáp án chuẩn như toán, vật lý và mã hóa.
Tuy nhiên, nhiều ứng dụng liên quan đến các vấn đề mở, thiếu giải pháp rõ ràng và phần thưởng có thể định lượng được. Các nhà nghiên cứu của Alibaba viết: “Chúng tôi mong muốn nâng cao ranh giới của LLM hơn nữa, nâng cao khả năng suy luận của họ để giải quyết những thách thức phức tạp trong thế giới thực”.
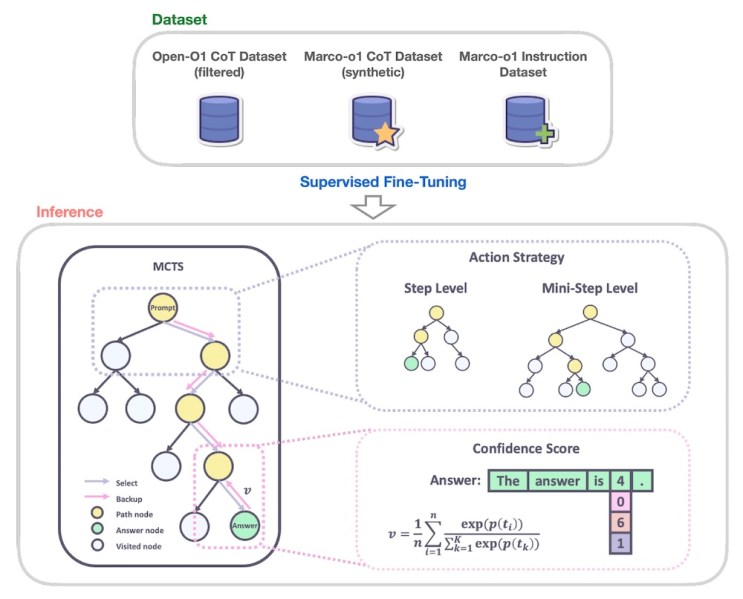
Marco-o1 là phiên bản tinh chỉnh của Alibaba Qwen2-7B-Hướng dẫn tích hợp các kỹ thuật tiên tiến như chuỗi suy nghĩ (CoT) tinh chỉnh, Tìm kiếm cây Monte Carlo (MCTS) và các chiến lược hành động lý luận.
Các nhà nghiên cứu đã đào tạo Marco-o1 về sự kết hợp của các bộ dữ liệu, bao gồm Mở-O1 Bộ dữ liệu CoT; bộ dữ liệu Marco-o1 CoT, bộ dữ liệu tổng hợp được tạo bằng MCTS; và tập dữ liệu Hướng dẫn Marco-o1, một tập hợp dữ liệu tuân theo hướng dẫn tùy chỉnh cho các tác vụ suy luận.

MCTS là một thuật toán tìm kiếm đã được chứng minh là có hiệu quả trong các tình huống giải quyết vấn đề phức tạp. Nó khám phá các đường dẫn giải pháp khác nhau một cách thông minh bằng cách liên tục lấy mẫu các khả năng, mô phỏng kết quả và dần dần xây dựng cây quyết định. Nó đã được chứng minh là rất hiệu quả trong các vấn đề AI phức tạp, chẳng hạn như đánh bại trò chơi cờ vây.
Marco-o1 tận dụng MCTS để khám phá nhiều đường dẫn lý luận khi nó tạo ra mã thông báo phản hồi. Mô hình sử dụng điểm tin cậy của mã thông báo phản hồi của ứng viên để xây dựng cây quyết định và khám phá các nhánh khác nhau. Điều này cho phép mô hình xem xét nhiều khả năng hơn và đưa ra kết luận sáng suốt và sắc thái hơn, đặc biệt là trong các tình huống có giải pháp mở. Các nhà nghiên cứu cũng giới thiệu một chiến lược hành động suy luận linh hoạt cho phép họ điều chỉnh mức độ chi tiết của các bước MCTS bằng cách xác định số lượng mã thông báo được tạo tại mỗi nút trong cây. Điều này mang lại sự cân bằng giữa độ chính xác và chi phí tính toán, mang lại cho người dùng sự linh hoạt để cân bằng giữa hiệu suất và hiệu quả.
Một cải tiến quan trọng khác trong Marco-o1 là việc giới thiệu cơ chế phản chiếu. Trong quá trình suy luận, mô hình sẽ tự nhắc mình định kỳ bằng cụm từ “Đợi đã! Có lẽ tôi đã phạm một số sai lầm! Tôi cần phải suy nghĩ lại từ đầu.” Điều này khiến mô hình phải đánh giá lại các bước suy luận của nó, xác định các lỗi tiềm ẩn và tinh chỉnh quá trình suy nghĩ của nó.
Các nhà nghiên cứu viết: “Cách tiếp cận này cho phép mô hình đóng vai trò là nhà phê bình của chính nó, xác định các lỗi tiềm ẩn trong lý luận của nó”. “Bằng cách nhắc nhở mô hình đặt câu hỏi về kết luận ban đầu của nó một cách rõ ràng, chúng tôi khuyến khích mô hình thể hiện lại và tinh chỉnh quá trình suy nghĩ của mình.”
Để đánh giá hiệu suất của Marco-o1, các nhà nghiên cứu đã tiến hành thử nghiệm trên một số nhiệm vụ, bao gồm điểm chuẩn MGSM, một tập dữ liệu cho các bài toán phổ thông đa ngôn ngữ. Marco-o1 vượt trội đáng kể so với mô hình Qwen2-7B cơ bản, đặc biệt khi thành phần MCTS được điều chỉnh về mức độ chi tiết của mã thông báo đơn.

Tuy nhiên, mục tiêu chính của Marco-o1 là giải quyết những thách thức về lập luận trong các tình huống mở. Để đạt được mục tiêu này, các nhà nghiên cứu đã thử nghiệm mô hình dịch các cách diễn đạt thông tục và tiếng lóng, một nhiệm vụ đòi hỏi phải hiểu được các sắc thái tinh tế của ngôn ngữ, văn hóa và ngữ cảnh. Các thử nghiệm cho thấy Marco-o1 có thể nắm bắt và dịch các biểu thức này hiệu quả hơn các công cụ dịch thuật truyền thống. Ví dụ: người mẫu đã dịch chính xác một cụm từ thông tục trong tiếng Trung, nghĩa đen là “Giày này mang lại cảm giác như bước đi trên phân” sang nghĩa tương đương trong tiếng Anh là “Giày này có đế thoải mái”. Chuỗi suy luận của mô hình cho thấy cách nó đánh giá các ý nghĩa tiềm ẩn khác nhau và đưa ra bản dịch chính xác.
Mô hình này có thể hữu ích cho các nhiệm vụ như thiết kế và chiến lược sản phẩm, đòi hỏi sự hiểu biết sâu sắc và theo ngữ cảnh cũng như không có các tiêu chuẩn và số liệu được xác định rõ ràng.

Một làn sóng mô hình lý luận mới
Kể từ khi phát hành o1, các phòng thí nghiệm AI đang chạy đua để đưa ra các mô hình suy luận. Tuần trước, phòng thí nghiệm AI Trung Quốc DeepSeek đã phát hành R1-Lite-Xem trướcđối thủ cạnh tranh o1 của nó, hiện chỉ có sẵn thông qua giao diện trò chuyện trực tuyến của công ty. R1-Lite-Preview được cho là đánh bại o1 trên một số điểm chuẩn chính.
Cộng đồng nguồn mở cũng đang bắt kịp thị trường mô hình tư nhân, phát hành các mô hình và bộ dữ liệu tận dụng luật chia tỷ lệ thời gian suy luận. Nhóm Alibaba đã phát hành Marco-o1 trên Ôm Mặt cùng với một tập dữ liệu lý luận một phần mà các nhà nghiên cứu có thể sử dụng để đào tạo các mô hình lý luận của riêng họ. Một mô hình khác được phát hành gần đây là LLaVA-o1được phát triển bởi các nhà nghiên cứu từ nhiều trường đại học ở Trung Quốc, mang mô hình lý luận về thời gian suy luận vào các mô hình ngôn ngữ tầm nhìn nguồn mở (VLM).
Việc phát hành các mô hình này diễn ra trong bối cảnh không chắc chắn về tương lai của các quy luật chia tỷ lệ mô hình. Nhiều báo cáo khác nhau chỉ ra rằng lợi nhuận từ việc đào tạo các mô hình lớn hơn đang giảm dần và có thể gặp khó khăn. Nhưng điều chắc chắn là chúng ta chỉ mới bắt đầu khám phá khả năng mở rộng quy mô thời gian suy luận.
